Upgrading AiHello’s ML infrastructure boosts sales & cuts ad costs. New algorithms provide faster, more accurate bid forecasts from less data.

AiHello AutoPilot Machine Learning Upgrade. Part 1
Upgrading AiHello AutoPilot Machine Learning Infrastructure
As a part of iterative process to improve the bid forecast process and help improve sales while also reducing ad costs, we will be experimenting with new algorithms that not only can be more accurate but it can also provide faster responses on sparse data. This will allow our software to start providing accurate forecasts with just few days of data as opposed to the current infrastructure where we need at least 60 days of data before it can make reasonable forecasts.
- Introduction of Data
Two data tables were used for this analysis: 1) keyword historical sales and bids. (primary table) and 2) user and campaign information (currency information). The keyword-report contains 7 million records containing cost, sales, impressions, clicks over days. After combining the campaign information, all costs and sales are converted into USD currency,
The basic cleaning process is: 1) clean keyword text, 2) drop empty keyword text, 3) sum up sales, cost, click, impression for each keyword with the same match type and campaign id on a single day, 4) remove records with 0 click (no method to calculate CPC).
After the basic cleaning, CPC is calculated by cost/click; ACOS is calculated by cost/sales (=20 if sales = 0); CTR is calculated by clicks/impressions, CR is calculated by unit/clicks. Then the distributions of the data are summarized in Fig. 2. As highlighted, the differences between min and max are huge, which will affect the performance of the model in the future, so the data are normalized before inputting into machine learning models.
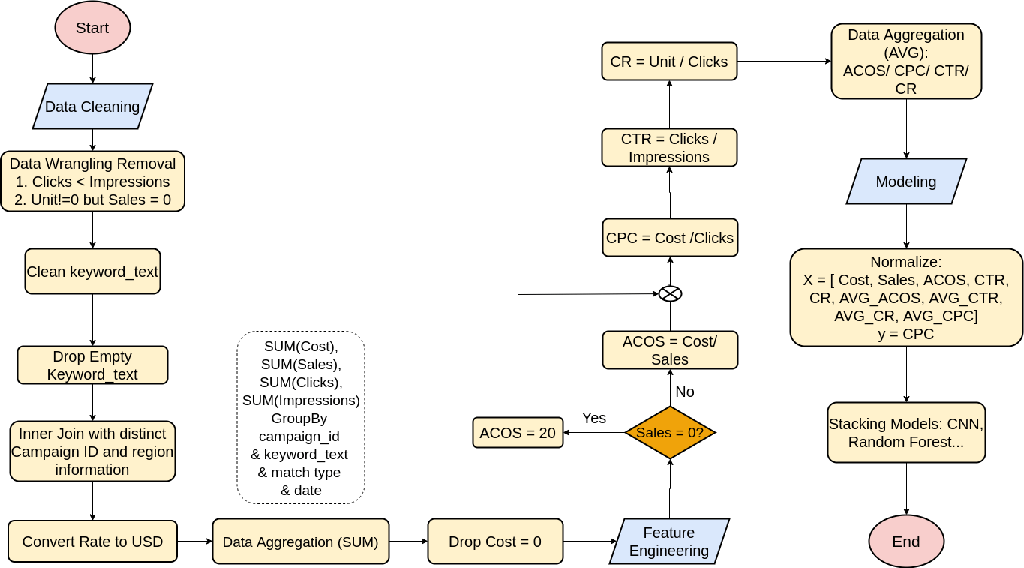
Fig. 1: Data Flow
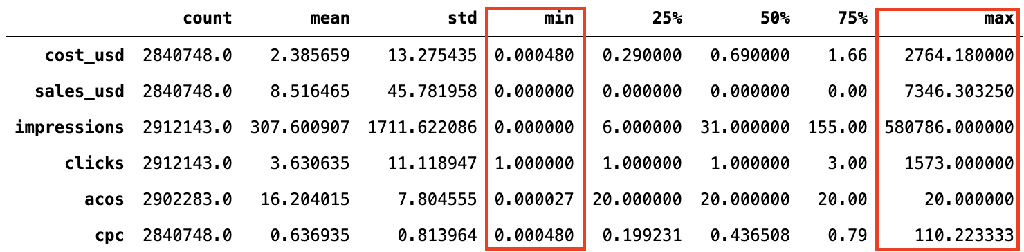
Fig. 2: Summary of descriptive statistics of data
- EDA (Exploratory data analysis)
2.1 Influences from match types
There are three types of amazon ad match types: 1) broad (keyword is matched to a user’s search term if all the keywords are present in it) , 2) exact (keyword is matched to user’s search terms if it is an exact match of the keyword), and 3) phrase (keyword is matched to a user’s search term if the keywords are present in the same order). This section aims to figure out if the match type will influence the sales and cost. As shown in Fig.3, the exact type has highest sales and clicks, and lowest ACOS (green line), which is better than the other two types. Then after counting the number of records in these three types (Fig. 4), most records are about the exact type, indicating that most people consider the exact better than the other two types as well.
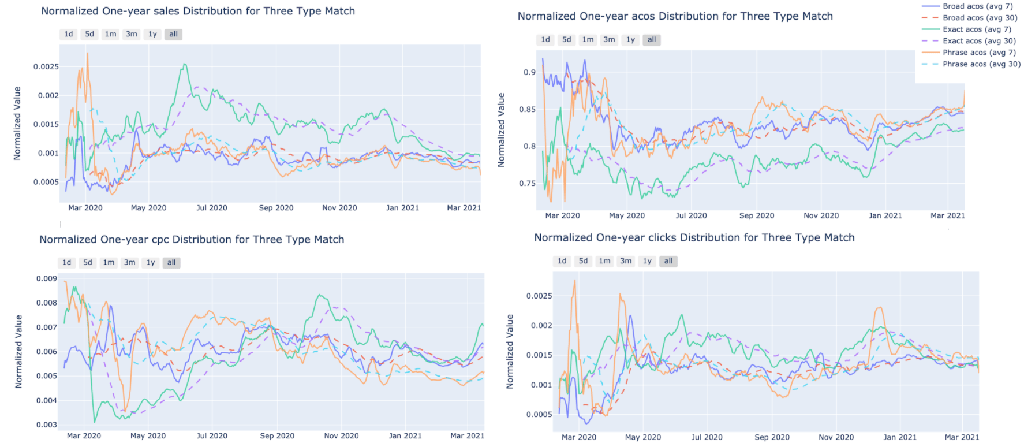
Fig. 3: Changes of sales, ACOS, CPC, and clicks over time in three match types
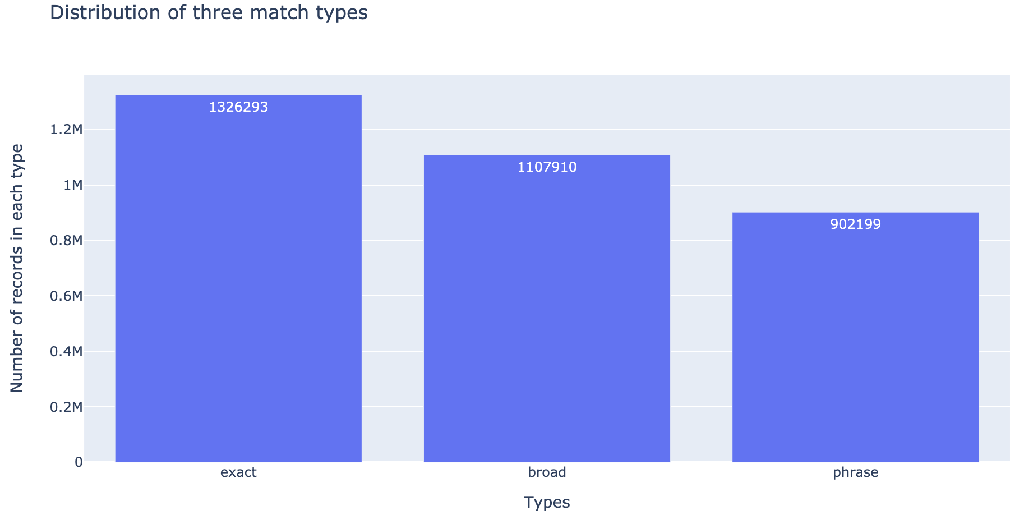
Fig. 4: Distribution of three match types
2.2 Influences from regions
The whole dataset covers the historical records in different regions such as Europe, United States, Canada, etc. Fig. 5 uses currency to represent curves in different regions. As shown, only USD has records from Jan. 2020 to Apr. 2021, records in other countries miss the early records. Also, the shoppers behavior in different regions are varied. For example, British (GBP represented by the purple curve) reached its peak sales in June 2020, and its curve is fluctuated in sales, ACOS, CPC, and clicks, which are quite different from others. In this case, the region can be one of the features for the prediction model. (This could be biased as our marketing efforts varied by region and the data fluctuation can potentially reflect it)
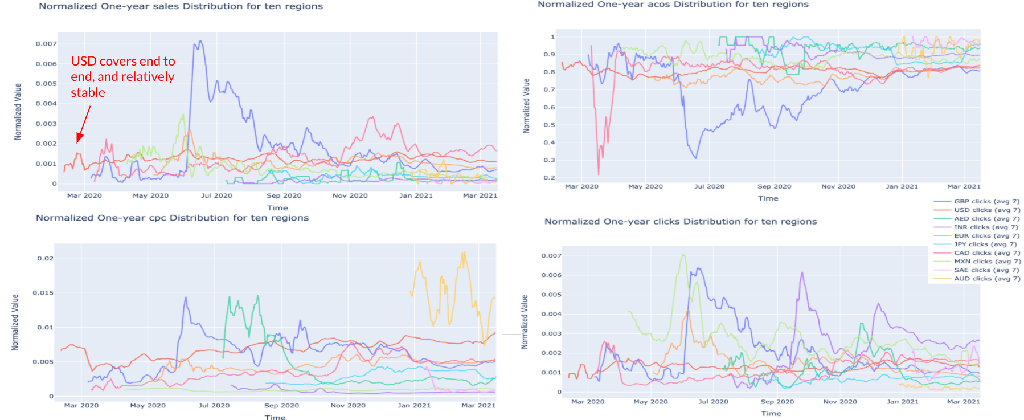
Fig. 5: Changes of sales, ACOS, CPC, and clicks over time in 10 regions.
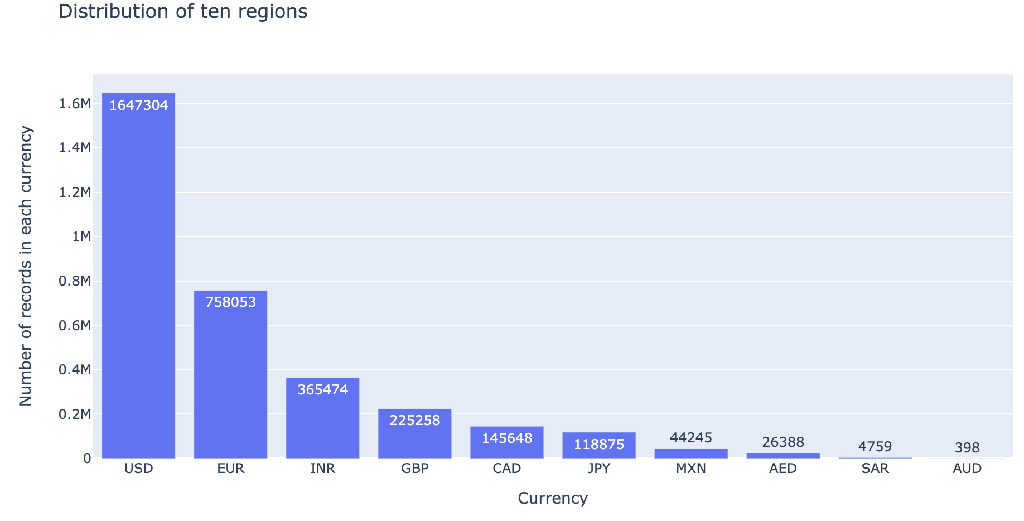
Fig. 6: Distribution of ten regions
2.3 CPC evaluation
As the target is to predict the future CPC, it’s essential to evaluate the time series data CPC as well. Based on the region evaluation, the records in USD currency have the longest history, so we decided to use USD CPC as the target in this section. Fig. 7 represents the min, max, mean, and mode CPC over the time. The left top corner pic shows a scatter with pretty high CPC (raw zinc at CPC = 110). The value isn’t reliable, so this record is removed, and then get the new pic as shown at the left bottom corner. However, even after removing the bias, curves for min, mode, and mean are almost overlapped and far away from the max curve. It indicates the distribution of the USD CPC is actually a positive skew. This might lead to some problems for the prediction and potential time series modelling. In this case, we tried to log CPC two times and filter out outliers to check if it helps improve the performance of models.
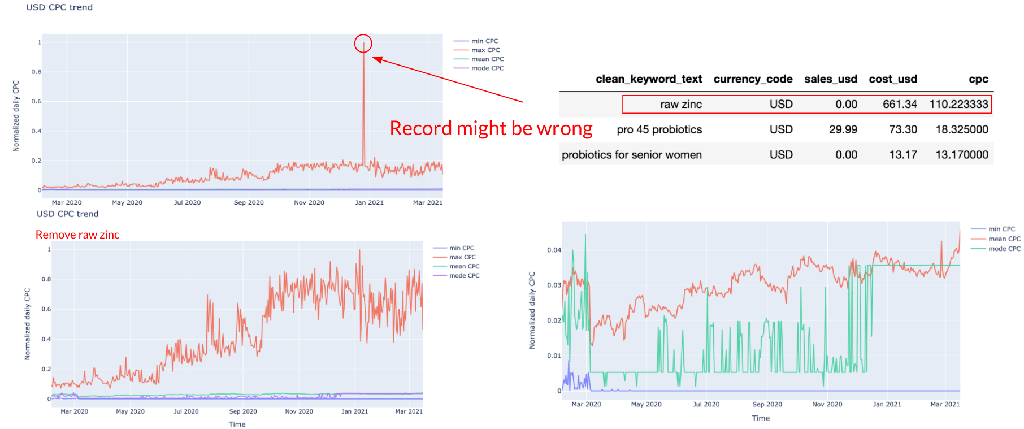
Fig. 7: Evaluation of CPC over the time
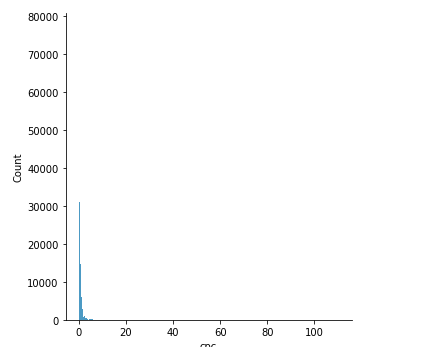 |  |
| (a) | (b) |
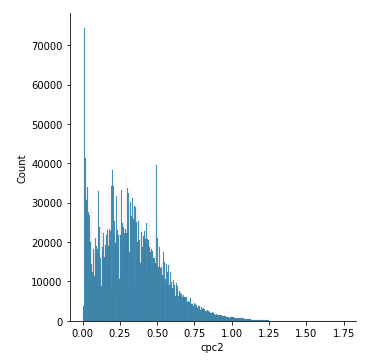
Fig. 8: Distribution of CPC (a) before two times log, and (b) after two times log
- Machine Learning Models
3.1 Models
Linear regression, random forest, CNN, lasso regression, gradient boost, XGBoost, and LightGBM are selected to predict the future CPC. The input and output are summarized in Fig. 9. The normalized cost, sales, acos, ctr, cr, and averaged values of these parameters are the input; CPC is the output. Both standard and robust scalars are tried to determine which one is better for the models.
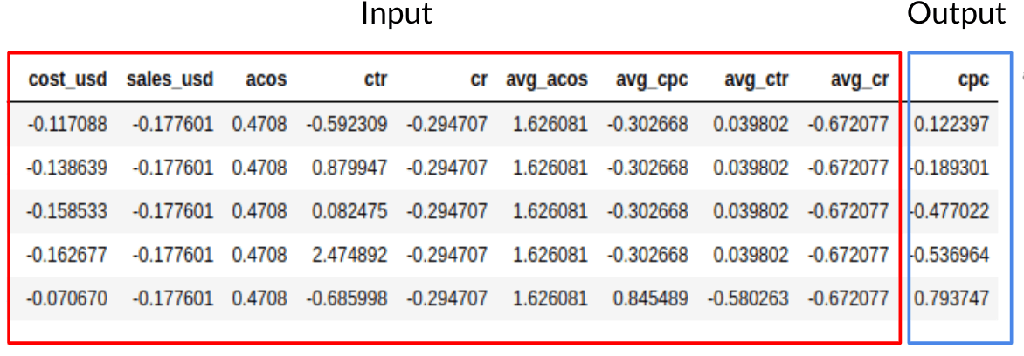
Fig. 9: Input and output of the models
3.2 Results
Fig. 10 summarizes the results generated by different machine learning models with standard scaler or robust scaler. In general, the models with standard scaling have lower RMSE, MSE, and MAE, so the standard scaler performs better than the robust scaler. When comparing standard scaler and twice log transformation, MAE is further reduced by transferring positive skew into normal distribution.
When comparing between different models, random forest performs best among the all.
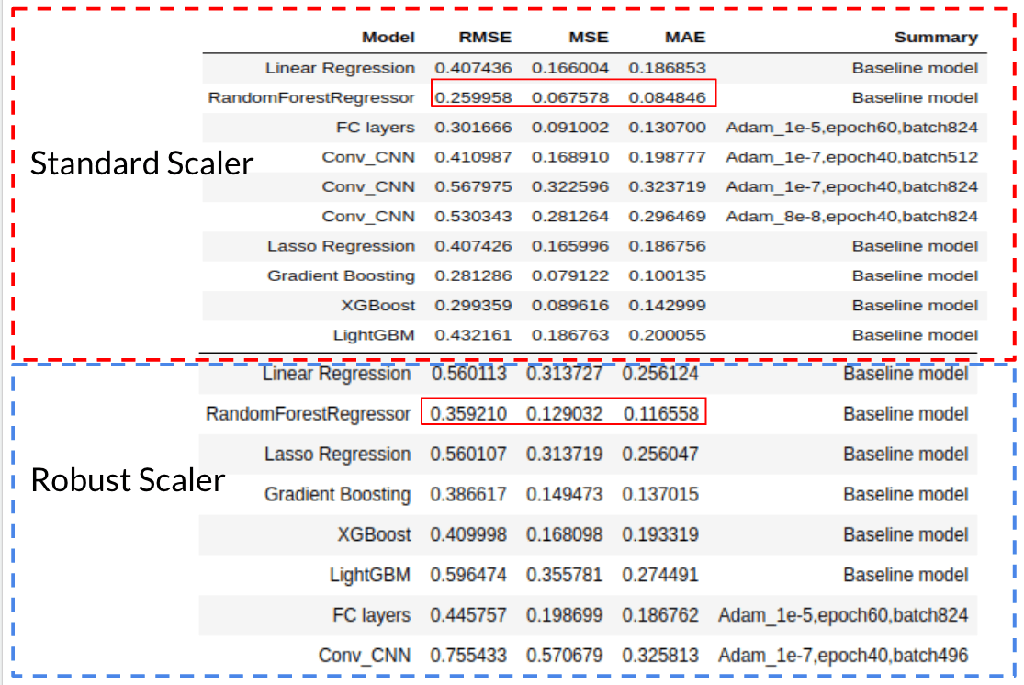
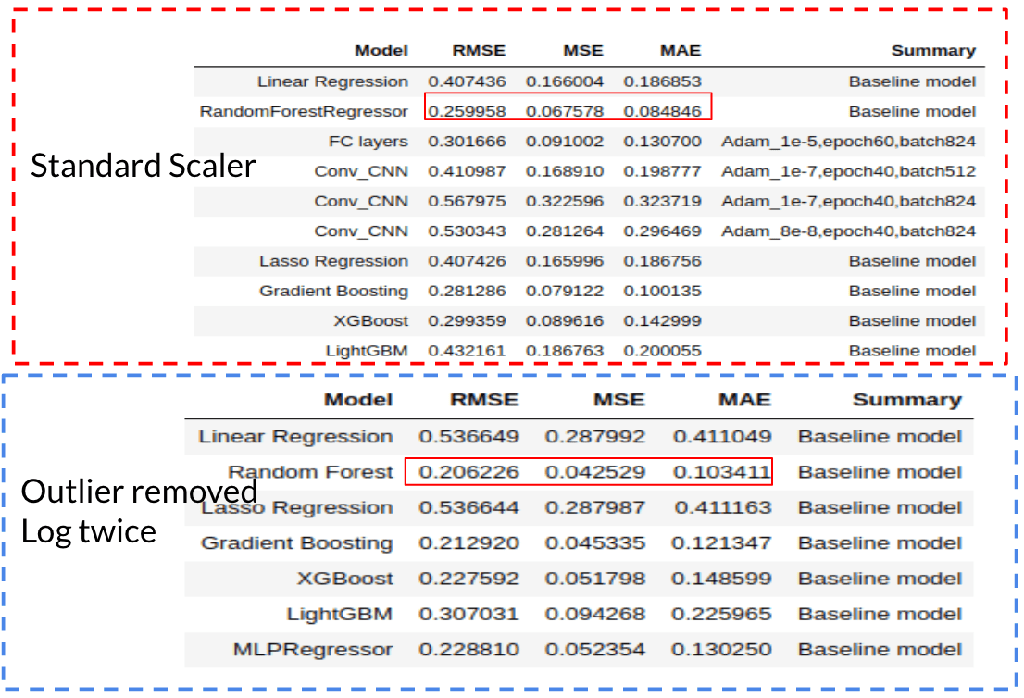
Fig. 10 Results of different machine learning models
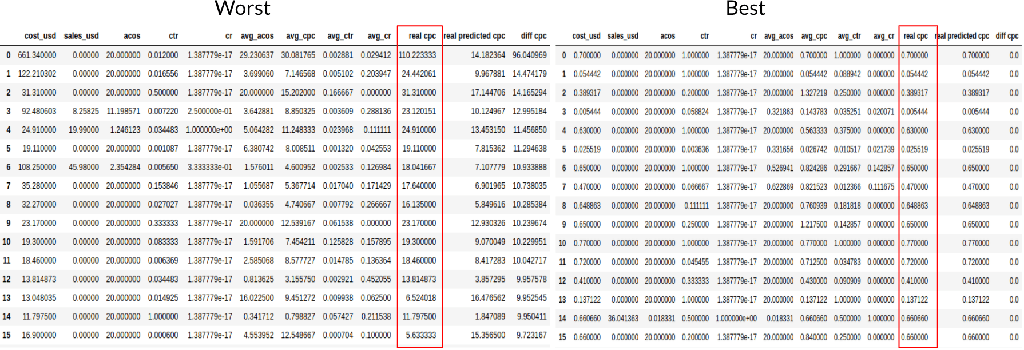
Then we evaluated the worst and best cases of random forest with a standard scaler. As shown in Fig. 11, the model cannot predict high value CPCs pretty well, but it can predict low value CPCs accurately. It might be due to the positive skewness of CPCs. In addition, since the CPCs with higher than 10 values aren’t reliable (in most cases CPCs are lower than 10), our next step is to filter out these high CPCs and retrain the models to check the results.
This concludes step 1 of our ML infrastructure upgrade.
Key take aways
1) Its better to focus on Exact keywords as they are generate higher revenues for slightly more expensive CPC
2) Simpler algorithms (Random Forest Regressor) can be more efficient and accurate as compared to Neural Networks and Deep Learning (CNN)
3) Adding time component might change in favor or Neural Networks especially LSTM

